
2Prolog (Pure Prolog)
2.1Grundkonzepte (Datenbank-Prolog)
Die Programmiersprache Prolog (Programming in Logic) wurde von A. Colmerauer (Marseille) und R. Kowalski (London) im Jahre 1972 entwickelt. Sie basiert auf der theoretischen Basis der mathematischen Logik (Prädikatenlogik 1. Ordnung).
Prolog kann mit einem sehr mächtigen "Datenbanksystem" verglichen werden. In einer Prolog-Datenbank werden Fakten über Objekte (Eigenschaften), Relationen zwischen Objekten und Ableitungsregeln gespeichert. Dann können Fragen zu diesem gespeicherten "Wissen" gestellt werden. Die Speicherungs- und die Abfragesprache sind die gleichen (eben Prolog). Mittels der Ableitungsregeln können Sachverhalte hergeleitet werden, die nicht explizit gespeichert sind.
Beispiel (Familienbeziehungen):
vater( philip, charles). /* Fakt: Philip ist Vater von Charles */
vater( philip, anne). /* Fakt: Philip ist Vater von Anne */
mutter( elizabethII, charles). /* Fakt: ElizabethII ist Mutter von Charles */
eltern( V, M, K) :-
vater( V, K),
mutter( M, K).
/* Regel: V und M sind Eltern des Kindes K,
wenn V der Vater und M die Mutter von K sind */
Fragen:
?- vater( philip, charles). ⇒ yes
?- vater( charles, philip). ⇒ no
?- vater( philip, K). ⇒ K = charles; K = anne; no
?- eltern( V, M, charles). ⇒ V = philip, M = elizabethII; no
Die Prolog-Datenbank besteht aus Fakten und Regeln.
Ein Fakt ist eine bekannte,
wahre Aussage, die in der Form
P.
geschrieben wird, wobei P ein "Prädikat" ist.
Ein "Prädikat" ist eine Aussage,
die wahr oder falsch sein kann.
Eine Regel ist eine
wahre logische Implikation der Form:
P :- P1, P2, ... Pn.
P und P1, P2, ... Pn sind Prädikate; P ist der Kopf (Head) und P1, P2, ... Pn ist der Körper (Body) der Regel. Das Zeichen ':-' bedeutet die Implikation '<=' und das Komma bedeutet 'und'. Die ganze Regel bedeutet "Wenn P1 und P2 und ... Pn wahr sind, dann ist auch P wahr", resp. "(P1 und P2 und ... Pn) impliziert P".
Fragen (Abfragen, Ziele, Queries, Goals) beginnen mit dem Symbol '?-'. Fakten und Regeln bilden die Programmklauseln. Fakten, Regeln und Fragen sind Klauseln.
Im Beispiel sind philip und charles Konstanten (beginnen mit einem Kleinbuchstaben). Konstanten bezeichnen bestimmte feste Objekte.
V, M und K sind Variablen (beginnen mit einem Grossbuchstaben). Variablen stehen für beliebige Objekte. Ihre Bedeutung ist lokal zur Klausel. Es gibt keine globalen Variablen. Eine Variable in einer Klausel bezeichnet ein und dasselbe Objekt. Zwei verschiedene Variablen können dasselbe Objekt bezeichnen.
vater( philip, charles) und eltern( V, M, K) sind im obigen Beispiel Prädikate, die aus einem Prädikatennamen (z.B. vater) und aus Argumenten bestehen. Die Anzahl der Argumente heisst Arität des Prädikats. Prädikate sind Aussagen über Objekte, die "wahr" oder "falsch" sein können. Prädikate haben syntaktisch die Form von Strukturen, die aus einem Funktor (z.B. vater) und aus Argumenten (z.B. philip, charles) bestehen.
Konstanten, Variablen und Strukturen sind Terme.
Unifikation (=)
Gleichmachen von zwei Termen durch Bindung von Variablen an Terme (Substitution). Beispiel:
?- vater( philip, K) = vater( V, charles). ⇒ V = philip, K = charles
Resolution
Resolution ist die Prolog-Lösungsmethode. Sie besteht aus dem Ersetzen eines Ziels durch den Körper einer Regel, dessen Kopf mit dem Ziel unifiziert (im Körper wird dabei die Substitution auch durchgeführt). Wenn ein Teilziel mit einem Fakt unifiziert, dann wird es als erfüllt aus dem Ziel gestrichen.
Beispiel:
| Ziel (Frage): | ?- eltern( V, M, charles) |
| Resolution mit der Regel: | ?- vater( V, charles), mutter( M, charles) |
| Resolution mit Fakt 1: | ?- (true), mutter( M, charles) |
| Resolution mit Fakt 3: | ?- (true). |
2.2Semantik und Backtracking
Deklarative Semantik
Fakten sind wahre Prädikate. Regeln sind wahre Implikationen, die bedeuten:
Wenn Körper wahr ist, dann ist Kopf wahr.
Resp.: Kopf ist wahr, wenn Körper wahr ist. Körper impliziert Kopf.
Der Körper ist wahr, wenn alle Prädikate, aus denen er besteht ("Teilziele"), wahr sind (Komma ist die Konjunktion "und"). Eine Frage "?- Q1, Q2, ... Qn" bedeutet "Ist Q1 und Q2 und ... und Qn wahr ?". Die Prolog-Antwort YES bedeutet, dass "Q1 und Q2 und ... und Qn" wahr ist. Die Antwort NO wird interpretiert als "Q1 und Q2 und ... und Qn" ist falsch. Diese Semantik wird später noch präzisiert.
Ein Goal G ist wahr, genau wenn:
- G unifiziert mit einem Fakt
- Es gibt eine Regel G' :- G1', G2', ... Gn'
und G unifiziert mit G' unter Substitution S
und alle Gi' (Gi = Gi' unter Substitution S) sind wahr.
Beide Möglichkeiten 1) und 2) beinhalten Nichtdeterminismus. Ein Goal kann mehrere Lösungen haben, z.B.:
?- vater( philip, K) ⇒ K = charles; K = anne
Prozedurale Semantik
Die Frage "?- Q1, Q2, ... Qn" wird als ein Befehl interpretiert: Löse Q1, dann Q2, dann ... Qn. Qi heissen Ziele (Goals). Ein Qi wird gelöst, wenn es ein Fakt ist, oder wenn es der Kopf einer Regel ist, und der Körper der Regel gelöst wird. Die Suche nach den passenden Fakten und Regeln findet von oben nach unten in der Datenbank statt. Dabei werden alle Fakten und Köpfe von Regeln berücksichtigt, die mit Qi "unifizieren" (matchen). Der Körper einer Regel wird gelöst, indem alle Teilziele von links nach rechts gelöst werden. Die Prolog Lösungsstrategie ist also top-down, left-to-right:
- Suche passende Fakten und Regeln von oben nach unten (top-down)
- Löse Subgoals von links nach rechts (left-to-right)
Prozedurale Semantik (Prolog Ausführung, Backtracking)
Betrachte ?- Q1, Q2, ... Qn. Nehme an, dass Q1, ... Qi-1 gelöst wurden und Qi zu lösen ist. Dies wird durch CALL Qi gekennzeichnet. Die Lösung von Qi ergibt Success (EXIT Qi) oder Failure (FAIL Qi). Im Falle von Success, wird zu CALL Qi+1 mit den Variablenbindungen fortgeschritten, die in Qi gemacht wurden. Im Falle von Failure, wird zu Qi-1 zurückgekehrt ("Backtracking") und versucht, für Qi-1 andere Lösungen zu finden (REDO Qi-1). Dabei werden die Variablenbindungen, die von Qi-1 stammten, zurückgenommen (die Variablen werden entbunden). Die Antwort YES bedeutet "Success", die Antwort NO bedeutet "Failure".
Beispiel:
d( X, Y) :- c( X, Y).
d( X, Y) :- b( Y, X).
c( X, Y) :- a( X), b( X, Y).
c( 0, 0).
a( a1).
a( a2).
a( a3).
b( a1, 1).
b( a1, 2).
b( a2, 3).
Beweisbaum (Proof Tree)
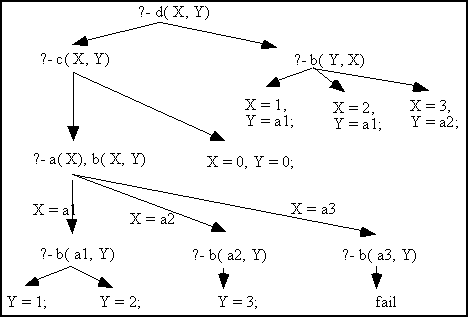
Fig. 2.1: Der Beweisbaum
Der Beweisbaum wird depth-first traversiert. Die Trace kann mit dem Prolog Interpreter ausgeführt werden.
Box-Modell
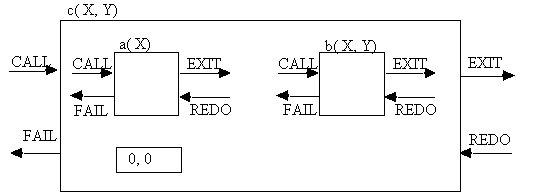
Fig. 2.2: Das Box-Modell
2.3Strukturen
Konstanten und Variablen sind Terme. Struktur ist ein (zusammengesetzter) Term: f( T1, T2, ... Tn); f: Funktor der Arität n; Ti: Argumente (Terme).Strukturbaum
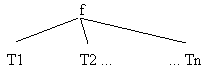
Fig. 2.3: Der Strukturbaum (Ti können weitere Strukturen sein)
Ti sind Blätter (Atome) oder weitere Teilbäume (Strukturen).
Beispiel:
person(
name( 'Hans', 'Meier'),
adresse( strasse( 'Landstr.', 7),
stadt( 'Bern')),
telefon( '031/1234 6'))
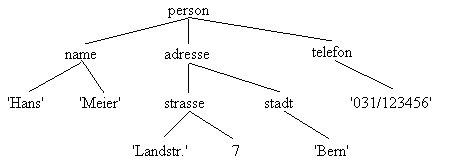
Fig. 2.4: Beispiel eines Strukturbaumes
Konstanten können beliebige Zeichen beinhalten, wenn sie in Quotes eingeschlossen sind. Variablen können an beliebige Strukturen gebunden werden. _ ist anonyme Variable. Zwei anonyme Variablen in einer Klausel haben miteinander nichts zu tun (als ob sie verschiedene Namen hätten).
Welche Tel.Nr. hat Hans Meier?
?- person( name( 'Hans', 'Meier'), _, telefon( TN)).
⇒ TN = '031 / 12 34 56'
?- person( name( 'Hans', 'Meier'), _, TN).
⇒ TN = telefon( '031 / 12 34 56')
Welche Adresse hat Hans Meier?
?- person( name( 'Hans', 'Meier), A, _).
⇒ A = adresse( ( strasse( 'Landstr.', 7), stadt( 'Bern'))
2.4Operatoren
Operator-Schreibweise:
| Beispiel | Erklärung |
|---|---|
| 1 + 2 | +: Operator (binär, infix) 1, 2: Operanden |
| - 1 | -: Operator (unär, präfix) |
| 3 ! | !: Operator (unär, postfix) |
Term-Schreibweise:
| Beispiel | Erklärung |
|---|---|
| '+'( 1, 2) | '+' ist ein Funktor der Arität 2 1 und 2 sind seine zwei Argumente |
| '-'( 1) | '-' ist ein Funktor der Arität 1 1 ist sein Argument |
| '!'( 3) | '!' ist ein Funktor der Arität 1 3 ist sein Argument |
Operatoren gestatten eine bequeme Schreibweise für Terme
(mit Funktoren der Arität 1 oder 2).
Vordefinierte Operatoren: +, -, >, <, =, is, ...
Benutzerdefinierte Operatoren (s. Teil 2).
"Gleichheit" Operatoren (Unifikation):
| X = Y | Die Terme X und Y unifizieren (die Unifikation wird durchgeführt) |
| X \= Y | Die Terme X und Y unifizieren nicht |
| X == Y | Die Terme X und Y sind identisch, d.h. alle gleiche Variablen sind instantiiert zu gleichen konstanten Termen, oder sie sharen; und es gibt keine anderen Variablen. Dies ist ein reiner Test; es wird keine Unifikation durchgeführt. |
| X \== Y | Die Terme X und Y sind nicht identisch. Dies ist ein reiner Test; es wird keine Unifikation durchgeführt. |
Beispiele:
?- X = a. ⇒ X = a
?- a( X) = a( 1). ⇒ X = 1
?- a( X, b( Y)) = a( c( Z), Z), d( Z) = d( b(1)).
⇒ X = c( b(1)), Y = 1, Z = b( 1)
Beachte:
?- X = 1 + 2. ⇒ X = 1 + 2
?- X = X + 1. ⇒ no
?- 3 = 1 + 2. ⇒ no
?- 1 + 2 = 1 + X. ⇒ X = 2 /* nur Unifikation; keine Rechnung ! */
Arithmetische Vergleiche <, >, >=, =<
Vergleich von zwei Zahlen oder instantiierten Variablen.
Arithmetische Operatoren +, -, *, /, .., is
Arithmetische Auswertung: Evaluationsoperator is
?- X is T. /* evaluiere Term T, unifiziere Resultat mit X */
?- X is 1 + 2. ⇒ X = 3
?- X = 1, X is X + 1. ⇒ no /*Variable hat nur einen Wert ! */
?- X = 1, Y is (X + 1) * 3. ⇒ X = 1, Y = 6
?- 3 is 1 + 2. ⇒ yes
?- 1 + 2 is 1 + 2. ⇒ no
Funktionen
Mathematik: f( x, y) = x + y + 1
Prolog:
f( X, Y, F) :- F is X + Y + 1. /* Relation */
?- f( 1, 2, F). ⇒ F = 4
?- f( X, 2, 4). ⇒ no /* der is-Operator ist nicht invertibel */
Beispiel: Minimum von zwei Zahlen.
/*a*/
min( X, Y, M) :- M = X, X =< Y.
min( X, Y, M) :- M = Y.
?- min( 1, 2, M). ⇒ M = 1; M = 2 /* FALSCH ! */
/*b*/
min( X, Y, M) :- M = X, X =< Y.
min( X, Y, M) :- M = Y, X > Y.
/* Richtig, aber ineffizient:
der Test (X =< Y) sollte vor der Berechnung (hier trivial: M = X) durchgeführt werden. */
/*c*/
min( X, Y, M) :- X =< Y, M = X.
min( X, Y, M) :- X > Y, M = Y.
/* Richtig, aber unschön:
die explizite Unifikation (M = X) ist überflüssig. */
/*d*/
min( X, Y, X) :- X =< Y.
min( X, Y, Y) :- X > Y.
/* Richtig und schön:
DAS Prolog Programm ! */
/*e*/
min( X, Y, X) :- X =< Y.
min( X, Y, Y) :- X >= Y.
/* Richtig aber ineffizient durch Redundanz. Betrachte:
g:- g1, g2, … gn.
Und alle gi haben 2 identische Lösungen => 2n identische Lösungen */
/*f*/
min( X, Y, X) :- X =< Y, !.
min( X, Y, Y).
/* Das in der Praxis verwendete Programm.
Effizient, aber leider prozedural wegen '!' ("Cut"). Erklärung später. */
2.5Terme
Alle Prolog Objekte sind syntaktisch Terme:
Term:
- Konstante:
- Atom:
- normal (z.B. a1, b)
- quoted (z.B. 'A', '$1')
- spezial (z.B. ->, ---)
- Zahl (z.B. 1, -1.2, 1.2e-3)
- String (z.B. "A", "ab")
- Atom:
- Variable (z.B. Ab, X1, ..)
- Struktur f( T1, T2, ... Tn), wobei f = Atom, Ti = Terme
- Ausdruck: T1 op T2, op T1, T1 op, wobei op = Atom, Ti = Terme
- Liste: [], [T1, T2, ...], wobei Ti = Terme
- (Term)
Auch Regeln und Fragen sind Terme:
| Regel: | P op1 P1 op2 P2 op2 ... op2 Pn, wobei op1 = :-, op2 = , |
| Frage: | op1 P1 op2 P2 op2 ... op2 Pn, wobei op1 = ?-, op2 = , |
2.6Listen
Beispiel einer Liste: [a, b, c].
Allgemeine Liste:
- entweder leer []
- oder [T1, T2, .... Tn] (dabei sind Ti Terme, also auch z.B. Listen)
T1 ist der Kopf
(Head, [T2, ... Tn] ist die
) Restliste
(Tail).
[T1, T2, .... Tn] = ( H . T ) ⇒ H = T1, T = [T2, ... Tn].
Notation [ H | T ]: H ist Head (Term); T ist Tail (Restliste).
Erweiterung: [T1, T2, ... Tn| T] = Liste mit den n ersten Elementen T1, T2, ... Tn
und der Restliste T.
Beispiele der Unifikation mit Listen:
[ X| Y] = [ 1, 2] ⇒ X = 1, Y = [2] /* nicht Y = 2 ! */
[ X| Y] = [ a] ⇒ X = a, Y = []
[ X| Y] = [ [a, b], [c]] ⇒ X = [ a, b], Y = [ [ c ]]
[ X] = [ 1] ⇒ X = 1
[ X] = [ 1, 2] ⇒ no
[ X] = [ ] ⇒ no
[ X1, X2, X3| X] = [ 1, 2, 3, 4]
⇒ X1 = 1, X2 = 2, X3 = 3, X = [ 4]
2.7Rekursion
Rekursion bedeutet das Zurückführen eines Problems auf ein strukturell gleiches aber einfacheres Problem, bis ein triviales Problem (Rekursionsverankerung, Abbruchbedingung) entsteht, das direkt lösbar ist.
Betrachte vier Prolog-Formulierungen der Aussage: "VF ist Vorfahre des Menschen M, wenn er ein Elternteil (Vater oder Mutter) von M ist, oder wenn er ein Vorfahre des Elternteils E von M ist."
/*a*/
vorfahre( VF, M) :-
elternteil( VF, M). /* Abbruchbedingung */
vorfahre( VF, M) :-
elternteil( E, M),
vorfahre( VF, E).
/*b*/
vorfahre( VF, M) :-
elternteil( E, M),
vorfahre( VF, E).
vorfahre( VF, M) :-
elternteil( VF, M). /* Abbruchbedingung */
/*c*/
vorfahre( VF, M) :-
elternteil( VF, M). /* Abbruchbedingung */
vorfahre( VF, M) :-
vorfahre( VF, E),
elternteil( E, M).
/* Linksrekursion: gefährlich. Statt 'no' terminiert nicht!*/
/*d*/
vorfahre( VF, M) :-
vorfahre( VF, E),
elternteil( E, M).
vorfahre( VF, M) :-
elternteil( VF, M). /* Abbruchbedingung */
/* Linksrekursion und Rekursion steht vor Abbruchbedingung:
terminiert nicht */
Alle vier Formulierungen sind logisch äquivalent. Wegen der prozeduralen Ausführung von Prolog sind nur a) und b) richtig (wobei die Version b oft weniger effizient ist). Als nützliche Heuristik gilt "mache einfache Dinge zuerst", d.h.: "Abbruchkriterium vor Rekursionsregel und Linksrekursion vermeiden".
Indirekte Rekursion:
p() :- ... q() ...
q() :- ... p() ...
Beispiel:
kind( K, E) :- elter( E, K).
elter( E, K) :- kind( K, E).
/* FALSCH: zirkulare Definition, terminiert nicht ! */
Symmetrische Relationen
Beispiel:
/* Definiere nachbar( S1, S2) = S1 ist Nachbar von S2 */
nachbar( schweiz, deutschland).
. . .
nachbar( S1, S2) :- nachbar( S2, S1).
/* FALSCH : statt 'no' terminiert nicht !*/
/* Richtig: neue Relation definieren ! : */
nachbarn( S1, S2) :- nachbar( S1, S2).
nachbarn( S1, S2) :- nachbar( S2, S1).
2.8Verarbeitung rekursiver Strukturen
Rekursion eignet sich zur Bearbeitung von rekursiv definierten Strukturen z.B. Listen und anderen zusammengesetzten Termen.
Beispiele:
member( X, Y) = X ist Mitglied der Liste Y:
member( X, [ X| _]).
member( X, [ _| Y]) :- member( X, Y).
Verständnis deklarativ. Ausführung prozedural.
?- member( X, [ 1, 2]). ⇒ X = 1; X = 2; no /* entspricht "do-Schleife" */
?- member( a( 1), [ a( X), Y]). ⇒ X = 1, Y = Y; X = X, Y = a( 1); no
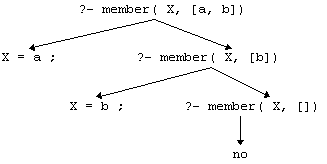
Fig. 2.5: Beweisbaum für member
append( X, Y, Z) = die Liste Z entsteht durch das Anhängen der Liste Y an die Liste X
append( [], Y, Y).
append( [ X1| Xs], Y, [ X1| Zs]) :-
append( Xs, Y, Zs).
Aufwand: O(n), n = Länge von X.
Beispiel:
?- append( [1], [2], Z). ⇒ Z = [1, 2]
?- append(X, Y, [1, 2]).
⇒ X = [], Y = [1, 2];
X = [1], Y = [2];
X = [1, 2], Y = []
?- append(X, Y, Z). /* generiert nichtinstanzierte Listen */
reverse( X, Y) = Y ist die umgekehrte Liste zu X
reverse( [], []).
reverse( [ X1| Xs], Y) :-
reverse( Xs, Ys),
append( Ys, [ X1], Y).
Aufwand R(n) = R(n-1) + A(n-1) = R(n-2) + A(n-2) + A(n-1) = ... =
= R(0) + A(0) + ... + A(n-1) = 1 + ... + n = O(n2), n = Länge von X.
?- reverse( R, [1, 2]). ⇒ R = [2, 1] /* invertibel */
rev( X, Y) = Y ist die umgekehrte Liste zu X.
Technik: "Iteration", "Akkumulation der Parameter"
rev( X, Y) :-
rev( X, [], Y).
rev( [ X1| Xs], R, Y) :-
rev( Xs, [ X1| R], Y).
rev( [], R, R).
Aufwand: O( n), n = Länge von X.
?- rev( R, [1, 2]). /* terminiert nicht !] */
2.9Unifikation und Resolution
Unifikation
Unifikation bedeutet das Gleichmachen von zwei Termen, indem gleiche Terme für gleiche Variablen substituiert werden. Zwei Terme unifizieren, genau wenn:
- Ein Term ist eine Variable, die nicht im anderen Term vorkommt ("occur check").
- Beide Terme sind die gleiche Konstante.
- Die Terme sind von der Form f( R1, ... Rn) und f( S1, ... Sn) und alle (Ri, Si) unifizieren.
| T1 | T2 = Konstante C2 |
|---|---|
| Konst. C1 | C1 = C2 |
| Var. X1 | X1 → C2 |
| Strukt. T1 | fail |
| T1 | T2 = Variable X2 |
| Konst. C1 | X2 → C1 |
| Var. X1 | X1 ↔ X2 sharen |
| Strukt. T1 | X2 → T1 occur check |
| T1 | T2 = Struktur T2 |
| Konst. C1 | fail |
| Var. X1 | X1 → T2 occur check |
| Strukt. T1 | T1 = f( R1, R2, ... Rn) T2 = f( S1, S2, ... Sn) R1 = S1, ..., Rn = S |
| T1 | T2 | ||
|---|---|---|---|
| Konstante C2 | Variable X2 | Struktur T2 | |
Konstante C1 | C1 = C2 | X2 → C1 | fail |
| Variable X1 | X1 → C2 | X1 ↔ X2 sharen | X1 → T2 occur check |
| Struktur T1 | fail | X2 → T1 occur check | T1 = f( R1, R2, ... Rn) T2 = f( S1, S2, ... Sn) R1 = S1, ..., Rn = Sn |
Die Unifikation X → T ( X Variable, T Term) ist nur möglich, wenn X nicht in T vorkommt (occur check).
Die Unifikation testet nicht nur ob zwei Terme unifizierbar sind, sondern berechnet auch die Liste der Substitutionen von Termen für Variablen, welche die zwei Terme gleichmacht. Nachfolgend ist nur zur Illustration ein Unifikationsalgorithmus angegeben.
Ein Unifikationsalgorithmus
Input: Terme R und T.
Output: Liste der Substitutionen S = [Var1 → Term1, ...],
die R und T unifizieren, oder Failure.
- Initialisiere: U := [ (R, T)]; S := []
- Entferne das erste Paar aus U. Nenne es (X, Y). (X, Y sind Terme)
- Falls einer der X, Y eine Variable ist, sei es X, dann: ersetze X in S und in U durch Y, und füge X → Y in S ein.
- Falls X = Konstante = Y, mache nichts.
- Falls X = f( X1, ..., Xn), Y = f( Y1, ..., Yn) für ein f und ein n, dann: füge (X1, Y1), ... ( Xn, Yn) am Anfang der Liste U ein.
- Sonst: Exit mit Failure.
- Wiederhole Punkt 2. bis U = [] oder Failure.
Der Unifikationsalgorithmus berechnet in der Liste der Substitutionen S den allgemeinsten Unifikator der zwei Terme R und T (most general unifier). Das heisst, falls es noch weitere Möglichkeiten gibt, R und T zu unifizieren, können sie alle aus S durch zusätzliche Bindungen abgeleitet werden.
Resolution
Resolution ist die wichtigste Methode des automatischen Theorembeweisens (Robinson, 1965). Resolution (für Horn Klauseln) besagt im Prinzip, dass ein Goal ?- G1, G2, ... Gn bewiesen wird, wenn:
- Ein Gj unifiziert mit einem Fakt F (unter einer Substitution S) und
das Goal ohne Gj, d.h.
?- G'1, ..., G'j-1, G'j+1, ..., G'n,
wird bewiesen. - Gj unifiziert mit dem Kopf A einer Regel A :- B1, ... Bm
(unter einer Substitution S) und das Goal, in dem Gj
durch B1, ..., Bm, ersetzt wurde, d.h.
?- G'1, ..., G'j-, B'1, ... B'm, G'j+1, G'n
wird bewiesen.
(B'i entsteht aus Bi und G'i entsteht aus Gi nach der Substitution S).
Nachfolgend ist nur zur Illustration ein Resolutionsalgorithmus angegeben.
Ein Resolutionsalgorithmus (für Horn Klauseln)
S = Liste der Substitutionen [ Var1 → Term1, ...]; G = Goal = Liste der Subgoals.
- Initialisiere S := [], G = [G1, ..., Gn].
- Nehme ein Goal Gj aus der Liste G.
- Nehme eine Klausel A :- B1, ..., Bm, die noch nicht versucht wurde, und deren Kopf A mit Gj unifiziert. Benenne die Variablen in dieser Klausel um, sodass neue Variablennamen entstehen. Die unifizierende Substitution sei [X1 → T1, ... Xk → Tk].
- Für i =1, ..., k:
Falls Xi in S ist, dann ersetze Xi durch Ti.
Falls Xi nicht in S ist, dann füge Xi → Ti in S ein. - Ersetze Gj in G durch B1, ...Bm.
- Ersetze alle Xi (i =1, ..., k) in G durch Ti.
- Wiederhole 2.-6. bis G = [] (Success) oder alle Klauseln in 3. versucht wurden (Failure). Das letztere benötigt Backtracking auf einem sequentiellem Rechner.
Bemerkungen:
- Die Wahl des zu lösenden Goals hat keinen Einfluss auf die Lösung, falls diese existiert und falls alle Klauseln, die matchen, auch einmal versucht werden. Dies kann z.B. durch die breadth-first Strategie erreicht werden.
- Die Wahl der Klausel in 3) hat keinen Einfluss auf das Resultat (ausser auf die Reihenfolge der Lösungen - Nichtdeterminismus), falls alle Klauseln einmal versucht werden (z.B. durch die breadth-first Strategie).
- Prolog verwendet eine feste Strategie für die Wahl der Goals und Klauseln. In 2) wird der erste Goal G1 (left-to-right), und in 3) die erste noch nicht versuchte Klausel von oben (top-down) gewählt. Dies führt dazu, dass nun die Reihenfolge der Subgoals ganz wesentlich ist. Sie bestimmt die Struktur des Beweisbaumes und entscheidet oft über das Terminieren (z.B. bei Linksrekursion). Die Reihenfolge der Regeln ändert nur die Suchreihenfolge im festen Beweisbaum; sie ändert nur die Reihenfolge der Lösungen, hat aber keinen Einfluss auf die Lösbarkeit. Der Prolog-Programmierer sollte vor allem Goals, aber auch Klauseln, richtig ordnen.
- Der allgemeine Resolutionsalgorithmus ist auch für den Beweis allgemeiner logischer Formeln (nicht nur Horn-Klauseln) anwendbar. Die Formeln müssen dazu zuerst in die sogenannte "Klauselform" transformiert werden.