
10Lernen
Lernen bezeichnet die Fähigkeit eines Systems (Mensch, Tier, Maschine) seine Leistung mit der Zeit zu verbessern, d.h. die gleiche Aufgabe (oder eine neue Aufgabe der gleichen Problemklasse) immer besser zu lösen.
Lernen:
- wesentliches Merkmal der menschlichen Intelligenz (⇒ kognitive AI)
- gewünschte Eigenschaft intelligenter Systeme (⇒ angewandte AI):
nicht alles explizit programmieren; Beispiele statt Regeln; ...
Arten des Lernens (in aufsteigender Folge der Inferenzmächtigkeit):
1) Instanzen auswendig lernen
Beispiel: Wörter einer Fremdsprache, Multiplikationstabelle bis 100, Wörterbuch Problematik: Speichern / Abrufen Das "Expertenparadoxon": Je mehr ein Mensch weiss, umso einfacher und schneller kann er benötigte Informationen "abrufen"; je mehr im Computer gespeichert wird, desto schwieriger ist das Wiederfinden.
2) Regeln auswendig lernen
Beispiel: Multiplikationsregel, if-then Regeln eines Expertensystems Problematik: Regeln müssen bekannt sein Speichern / Suchen (recognition, matching, etc. ⇐ ⇒ Inferenz)
3) Lernen aus Beispielen
Lernen aus Beispielen ist die wichtigste Art des Maschinenlernens. In einer Lernphase werden dem System Beispiele zusammen mit ihrer Klassifikation (Klassenzugehörigkeit) präsentiert. Aus diesen bekannten Beispielen sollte das System allgemeine Klassifikationsregeln lernen, die es später in der Klassifikationsphase auch auf unbekannte Beispiele anwenden kann. Beim Lernen eines "Konzepts" werden zwei Klassen unterschieden: positiv (das Konzept) und negativ (nicht das Konzept).
Beispiel:
| Lernphase: | positive Beispiele eines Konzepts: 0, 8, 9, 6, ... o, O, &, c ... negative Beispiele eines Konzepts: x, v, k, ... 1, 7, /, |, [, -, *, =, >, <, ... |
| gelernt: | Konzept = "Zahl" oder Konzept = "rund" (d.h. keine Ecken). |
| gelernt: | Klassifikationsregel = Wenn keine Ecken, dann liegt das Konzept vor (Klasse 1), sonst liegt es nicht vor (Klasse 2). |
| Klassifikationsphase: | Zuordnung eines neuen unbekannten Beispiels zu einer Klasse: "4" ⇒ Klasse 2 |
Lernen ist ein Induktionsprozess, bei dem vom Speziellen auf Generelles geschlossen wird. Diese Schlussfolgerung kann nicht mathematisch bewiesen werden. Sie kann darum falsch sein und muss unter Umständen durch neue Erkenntnisse revidiert werden. Demgegenüber ist die logische Deduktion (Schliessen vom Generellen auf Spezielles) logisch korrekt.
Lernen aus Beispielen hat unter den Lernverfahren die grösste praktische Bedeutung. Zu den verbreiteten Methoden gehören:
- statistische Klassifikationsverfahren ("parallele" Klassifikation: alle Attribute gleichzeitig verwendet)
Beispiele: Nearest Neighbor Classifier, Klassen-Prototypen, Separationsflächen - adaptive Verfahren
Beispiele: Perceptron, neuronale Netzwerke - Klassifikationsbäume
("sequentielle" Klassifikation: Attribute der Reihe nach verwendet)
Beispiel: ID3-Algorithmus
4) Lernen durch Entdeckung
Im Unterschied zum Lernen aus Beispielen ist die Zuordnung der Lernbeispiele zu Klassen nicht bekannt. Sie wird durch das System entdeckt (Clustering). Bildung neuer Konzepte und Theorien. Im obigen Beispiel wäre es die Entdeckung des Konzeptes "rund". Das wissensbasierte System AM kann mathematische Konzepte (z.B. gerade Zahl, Primzahl, etc.) entdecken (selbstvertändlich nicht so benennen).
10.1ID3-Algorithmus
Der ID3-Algorithmus ("Iterative Dichotomizer", Quinlan 1979, "Dichotomie" = Zweiteilung) gehört zu den sequentiellen Klassifikationsalgorithmen. ID3 basiert auf CLS ("Concept Learning System") von Hunt (1963). ID3 wird sehr häufig in Expertensystemen verwendet, die die Eigenschaft "Lernen von Regeln aus Beispielen" anbieten. Eine gute Beschreibung findet sich in: J. R. Quinlan: Learning Efficient Classification Procedures and Their Application to Chess End Games, in R.S. Michalski, T.M. Mitchell, eds.: Machine Learning, Tioga Publ. Co., Palo Alto 1979, 463-482.
Beispiel:
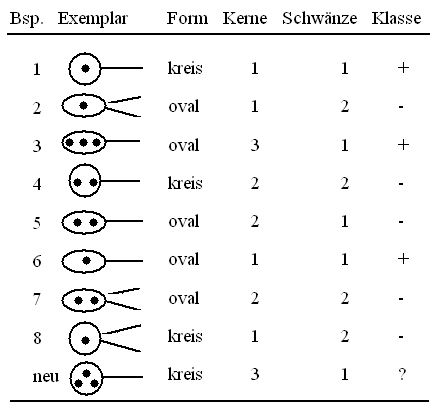
Fig. 10.1: Lernbeispiele
Beispiel einer Klassifikation: die Attribute werden der Reihe nach verwendet (Fig. 10.2).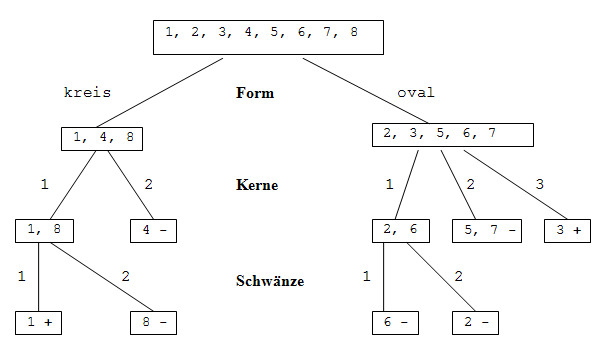
Fig. 10.2: Ein Klassifikationsbaum
Das neue Beispiel (Form = kreis, Kerne = 3, Schwänze = 1) wird approximativ der negativen Klasse zugeordnet, da unter dem Knoten (1, 4, 8) sich insgesamt mehr negative (2) als positive (1) Beispiele befinden. Der Baum ist schlecht: zu tief, viele Blätter (7) mit wenig Beispielen (ca. 1 Beispiel/Blatt), schwache Verallgemeinerung.
Klassifikationsbaum nach ID3:
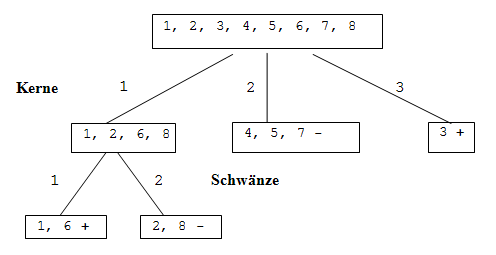
Fig. 10.3: ID3-Klassifikationsbaum
Das neue Beispiel (Form = kreis, Kerne = 3, Schwänze = 1) wird nun der Klasse + zugeordnet. Der Baum ist besser: 4 Blätter mit ca. 2 Beispielen/Blatt.
ID3-Verfahren: In jedem Knoten gibt es eine Menge von Beispielen B und eine Menge von noch nicht benutzten Attributen. Wähle das Attribut A (mit den Attributwerten a1, a2, ...an), das am besten die Beispiele separiert, d.h. die Beispiele in Teilmengen B1, ...Bn, aufteilt, sodass jede dieser Mengen möglichst viele Beispiele der einen Klasse und möglichst wenig Beispiele der anderen Klasse enthält.
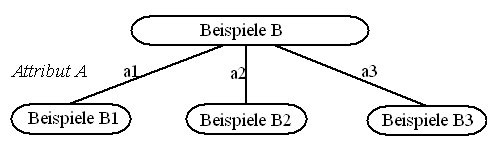
Fig. 10.4: ID3-Klassifikation
Das "Reinheitsmass" einer Menge von Beispilen wird mit Hilfe der Entropie E definiert (Fig. 10.5):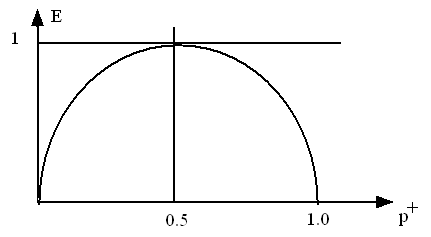
Fig. 10.5: Entropie
E (p+, p-) = - p+ ln(p+) - p- ln(p-) = - p+ ln(p)+ - (1 - p+) ln(1 - p+)
p+ = n+ / n
p+ = n- / n
n = n+ + n-
n+ = Anzahl positive Beispiele in der Menge
n- = Anzahl negative Beispiele in der Menge
Es gilt:
E (0, 1) = E (1, 0) = 0 (kleinste Unordnung, grösste Reinheit)
E (0.5, 0.5) = 1 = max (grösste Unordnung, kleinste Reinheit)
Die Durchschnittsreinheit der Aufteilung unter Benützung des Attributs A ist:
EA = P (a1) E1 + P (a2) E2 + ... (Summe über alle Werte des Attributs A)
wobei:
P (ai) = (ni+ + ni-) / n = ni / n, etc.
Ei = Entropie von Bi.
Der ID3-Baum minimiert die Entropie lokal bei der Aufteilung eines Knotens in Subknoten.